Fetching and Caching Data with Redis
•12 min read•By Saman Kefayatpour
In a recent project, I managed a database with two primary views: an infinite-scroll listing page and a detailed individual entity page (using a movie database as an example here).
Initially, my data fetching logic was straightforward, utilizing React's built-in cache function for basic request memoization:
export const getMovies = cache(async (page: number = 1): Promise<Movie[]> => { const result = await movieRepository.getMovies(page); return result; }); export const getMovie = cache(async (slug: string): Promise<Movie> => { const result = await movieRepository.getMovie(slug); return result; });
While this works, hitting the database for every single request isn't efficient as the application scales. To improve performance and reduce database load, I decided to implement Redis as a caching layer.
My first thought was to cache the entire result of a page using a unique key like movies:page:${page}.
export const getMovies = async (page: number = 1): Promise<Movie[]> => { const cacheKey = `movies:page:${page}`; const cachedMovies = await redis.get(cacheKey); if (cachedMovies) { return JSON.parse(cachedMovies); } const result = await movieRepository.getMovies(page); await redis.set(cacheKey, JSON.stringify(result)); return result; };
The Problem: This approach is rigid. Movies are sorted by release date; if a new movie is added or an existing one is updated, the entire page cache becomes stale. Invalidating and rebuilding large JSON blobs for every page is inefficient.
To solve this, I decoupled the pagination logic from the movie data.
Pagination Keys: movies:page:${page} stores only an array of movie slugs.
Data Keys: movie:${slug} stores the actual movie object.
This way, if one movie changes, I only update its specific key rather than every page it appears on.
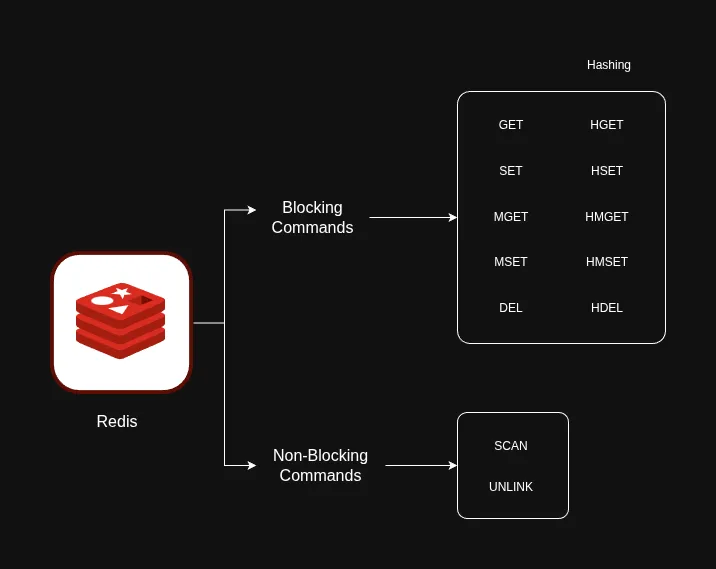
When dealing with multiple keys, simple GET and SET commands can become a bottleneck because Redis is single-threaded. Here are the optimizations I implemented:
Pipelines: Instead of sending multiple SET commands one by one, I use a pipeline to batch them into a single network request.
MGET: Used to fetch multiple movie objects simultaneously.
SCAN vs KEYS: To invalidate pagination when data changes, I avoid KEYS * (which is blocking) and use SCAN to find keys non-blockingly.
UNLINK vs DEL: I use UNLINK instead of DEL. UNLINK performs the actual memory reclamation in a different thread, making it much faster for large datasets.
const { key: PAGE_PREFIX, ttl: PAGE_TTL } = redisKeys.movies; const { key: POST_PREFIX, ttl: POST_TTL } = redisKeys.movie; export const movieCache = { getPageKey: (page: number) => `${PAGE_PREFIX}:${page}`, getMovieKey: (slug: string) => `${POST_PREFIX}:${slug}`, async setPageData(page: number, movies: Movie[]) { const pipeline = redis.pipeline(); const slugs = movies.map((m) => m.slug); pipeline.set(this.getPageKey(page), slugs, { ex: PAGE_TTL }); movies.forEach((movie) => { pipeline.set(this.getMovieKey(movie.slug), movie, { ex: POST_TTL }); }); await pipeline.exec(); return slugs; }, async invalidatePagination() { const pattern = `${PAGE_PREFIX}:*`; let cursor = 0; do { const [nextCursor, keys] = await redis.scan(cursor, { match: pattern, count: 100, }); cursor = Number(nextCursor); if (keys.length > 0) await redis.unlink(...keys); } while (cursor !== 0); }, };
To make the UI feel even snappier, I used Promise.allSettled to fetch missing items and the Next.js after function to handle cache updates in the background. This ensures the user doesn't wait for Redis write operations.
export const getMovies = cache(async (page: number = 1): Promise<Movie[]> => { const pageKey = movieCache.getPageKey(page); let slugs = await redis.get<string[]>(pageKey); // If page index is missing, fetch all from DB and cache if (!slugs) { const movies = await movieRepository.getMovies(page); await movieCache.setPageData(page, movies); return movies; } // Fetch what we can from Redis const movieKeys = slugs.map(movieCache.getMovieKey); const cachedMovies = await redis.mget<Movie[]>(...movieKeys); const moviePromises = slugs.map(async (slug, i) => { if (cachedMovies[i]) return cachedMovies[i]; return await movieRepository.getMovieBySlug(slug); }); const settledResults = await Promise.allSettled(moviePromises); const results: Movie[] = []; const itemsToCache: Movie[] = []; settledResults.forEach((result, i) => { if (result.status === "fulfilled" && result.value) { const movie = result.value; results.push(movie); if (!cachedMovies[i]) { itemsToCache.push(movie); } } else if (result.status === "rejected") { console.error(`Failed to fetch movie for slug: ${slugs[i]}`, result.reason); } }); // Background Cache Update if (itemsToCache.length > 0) { after(async () => { const pipeline = redis.pipeline(); for (const movie of itemsToCache) { pipeline.set(movieCache.getPostKey(movie.slug), movie, { ex: redisKeys.movie.ttl, }); } await pipeline.exec(); }); } return results; });
There is always room to grow. Here are two areas I'm looking at next:
HSET and HGET are more memory-efficient than storing strings and allow us to fetch only the fields we need.MSET for even faster bulk writes.Caching is a powerful tool, but it introduces complexity. By normalizing data and using non-blocking Redis commands like SCAN and UNLINK, we can build a system that is both fast and scalable. Redis has too many other collection types and commands like sets, sorted sets, stack, queues, pub/sub, and more that I haven't even scratched the surface of. I hope this helps anyone looking to optimize their own data layer!
As always, I may have missed some points or nuances, so if you have any questions or suggestions, please feel free to share them with me. I’m always open to learning and improving my knowledge alongside the community. Stay humble and keep learning!