The Mechanics of Build Tooling
•12 min read•By Saman Kefayatpour
As software engineers, we run npm run build dozens of times a day. We wait for the progress bar, check our output directory, and ship the assets. But between typing that command and generating those optimized files, a massive orchestration of computer science takes place.
If you ask a room of developers how this works, the terms compiler, transpiler, and bundler often get thrown around interchangeably. They aren't the same thing, but they have to talk to each other constantly.
To understand how code transforms from development to production, we have to look at the unified pipeline: how files are parsed into abstract syntax trees, how compilers manipulate them, and how bundlers stitch those trees into a cohesive application dependency graph.
A compiler or transpiler operates at the molecular, single-file level. It doesn’t care about your project architecture; its job is to translate code from one syntax to another (like TypeScript to ES6 JavaScript, or JSX into standard element calls).
To manipulate code safely without relying on fragile string matching or regular expressions, tools like Babel or SWC parse your source code into an Abstract Syntax Tree (AST).
An AST is a deeply nested tree structure that represents the grammatical layout of your code. If you write a simple function:
function add(a, b) { return a + b; }
A compiler’s parser breaks this text down into an object hierarchy:
[ Program ] | [ FunctionDeclaration ] (Identifier: "add") / \ [ Params ] [ BlockStatement ] / \ | (id: a) (id: b) [ ReturnStatement ] | [ BinaryExpression ] (Operator: "+") / \ (id: a) (id: b)
Once the code is a tree, the compiler runs transformers to walk the AST, modify nodes, inject new nodes, or delete them entirely.
OptionalMemberExpression (user?.name) and rewrites that branch of the tree into a standard ternary expression (user !== null && user !== undefined ? user.name : undefined) for older browser compatibility.a, b), and strips away unused whitespace nodes.While the compiler is busy morphing individual files, the Bundler (Webpack, Vite, Rollup) is managing the macro-level infrastructure. A browser cannot efficiently fetch thousands of isolated files; the bundler's job is to sew them together.
The bundler starts at a designated Entry Point (e.g., src/main.tsx). It parses the entry file's AST specifically looking for ImportDeclaration or ExportNamedDeclaration nodes.
[ src/main.tsx ] (Entry) / \ [ src/App.tsx ] [ src/styles.css ] / \ [ Button.tsx ] [ utils/math.ts ]
By tracing these import statements recursively across your codebase, the bundler maps the entire topology of your application into a Dependency Graph.
The true magic happens in how the compiler and bundler talk to each other. They do not work in isolation. In a traditional setup (like Webpack using babel-loader), the pipeline repeats a costly process:
main.js, parses its AST to find imports, and locates the next file.This constant parsing, stringifying, and re-parsing of ASTs creates a massive CPU bottleneck.
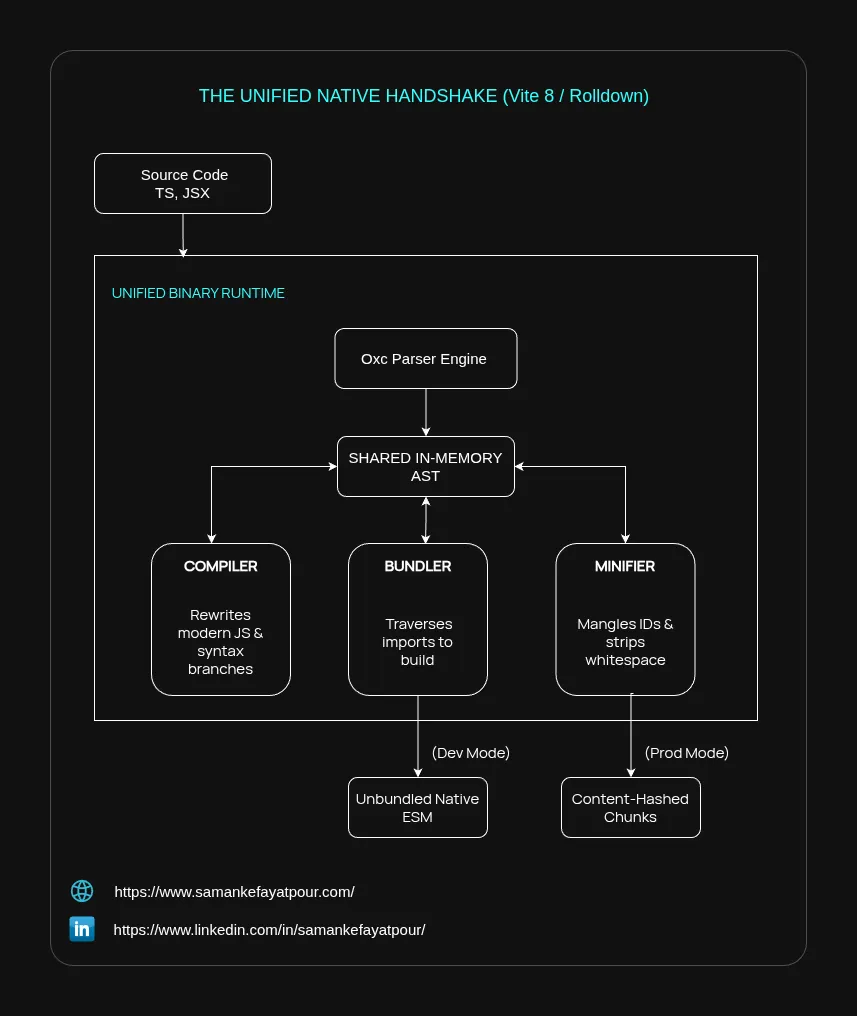
The modern frontend ecosystem resolved this bottleneck by merging the toolchain. With Vite 8 moving natively to Rolldown (a Rust-based bundler) backed by the Oxc compiler, the pipeline is compressed.
Because the bundler and compiler are part of the same binary architecture, a file is parsed into an AST once. The compiler transforms the syntax on that tree, and the bundler instantly uses that same exact AST in memory to read imports and build the dependency graph. This unified handshake is why modern pipelines build code up to 10–30x faster than traditional tools.
The tools we use to coordinate these transformations have evolved drastically, shifting from monolithic JavaScript bundlers to unified, native-language engines.
| Feature | Webpack | Vite (Legacy Split) | Vite 8+ (The Unified Era) |
|---|---|---|---|
| Development Paradigm | Bundles everything upfront before serving. | Unbundled native ESM for instant startup. | Unified, fast native bundling/serving. |
| Under the Hood | Pure JavaScript runtime. | Dev server via Esbuild (Go); Production via Rollup (JS). | Powered entirely by Rolldown (Rust) & Oxc (Rust). |
| Best Used For | Legacy setups with highly custom configurations. | Midsize older setups. | Modern SPA/SSR apps looking for maximum build speed. |
Once the bundler has the complete graph and the compiler has unified the files, the bundler executes its final optimization passes before writing code to disk.
Tree shaking is a structural exercise in dropping unused modules. It relies heavily on the static nature of ES Modules (ESM). Because import and export statements cannot change at runtime, the bundler analyzes the dependency graph statically.
If utils/math.ts exports an add function and a heavy complexCalculator function, but the graph shows complexCalculator has zero inbound lines targeting it, the bundler prunes that entire sub-branch from the final output tree.
Why CommonJS Fails: This is why older CommonJS (
require()) syntax is highly resilient to tree-shaking. Becauserequire()can be dynamic—wrapped inside a runtimeifstatement—the bundler cannot safely guarantee if code is needed until it executes.
Shipping a single, massive main.js file forces users to download your entire application just to view the landing page. Code Splitting splits the dependency graph into smaller sub-graphs called Chunks.
import('./pages/Dashboard') signals the bundler to break that node out into its own isolated asset file, loaded dynamically over the network only when requested.node_modules changes rarely compared to your UI components. Splitting third-party libraries into a vendor.js chunk ensures heavy assets stay cached on the user's browser across multiple application updates.To ensure users receive instant updates without losing long-term caching benefits, bundlers use Content Hashing. The bundler takes the finalized chunk code, computes a deterministic hash value, and writes it directly into the file name:
main.a8f9c2.js (Application logic — changes often)vendor.7e3b1a.js (Dependencies — changes rarely)If you modify a single line of application code, only main.js receives a new hash code (main.b2c4d9.js). The client browser instantly updates its reference to your file while pulling the unchanged, heavy vendor bundle directly from local cache.
(Note: If you are a junior or intermediate developer, feel free to skip this section! If you want to understand the deep underlying architectural compromises that forced the industry to change, read on.)
If you want to understand why the ecosystem underwent such a massive re-engineering effort over the last few years, we have to look closely at the two fundamental bottlenecks of second-generation build tools: The Dev/Prod Parity Gap and AST Serialization Overhead.
When Vite originally launched, it made a pragmatic compromise to maximize speed: it used Esbuild (written in Go) for lightning-fast dev-time syntax transforms, but handed the code to Rollup (written in JavaScript) for production chunking and tree-shaking.
While this made local development incredibly fast, it introduced an engineering nightmare: a complete lack of Dev/Prod Parity.
Because Esbuild and Rollup were two entirely separate codebases written by different authors in different languages, they handled edge-case module resolutions and CommonJS-to-ESM interop slightly differently. Teams frequently ran into bugs where an import path resolved perfectly on a local developer machine, only to mysteriously fail or throw runtime errors when compiled by Rollup in the production CI/CD pipeline.
To solve performance inside older ecosystems, developers initially tried dropping native tools directly into existing JS pipelines (e.g., using Webpack with an SWC loader). This exposed a hidden CPU tax: Serialization Overhead.
Every time a JavaScript-based bundler coordinates with a Rust-based compiler, the file data has to cross a bridge:
[JS Bundler] --(Serialize to String/JSON)--> [Rust Compiler (Parses to AST)] | [JS Bundler] <--(Stringify & Deserialize)-- [Transforms AST back to JS String]
Parsing a file into an AST, transforming it, turning it back into a string, and sending it back to Node.js to be parsed again by the bundler creates a massive performance tax. The CPU spends more time converting data formats across the JavaScript/Rust boundary than it does actually optimizing code.
This is why modern tooling architectures changed completely. With Vite 8 unifying its entire engine under Rolldown (a Rust bundler built by the VoidZero team) and pairing it with Oxc (an ultra-fast Rust parser), the entire pipeline is compressed into a single native execution context.
Every time your application loads instantly in a browser, it is due to a highly orchestrated sequence of code transformations. Understanding how strings of text become Abstract Syntax Trees, how compilers transform those trees, and how bundlers arrange them into dependency graphs strips away the "dark magic" of build tools. It leaves you with a predictable, performance-tuned system you can reason about, configure, and optimize with confidence.
As always, I may miss some points, so if you have any questions or suggestions, please feel free to share them with me. If you know a better approach, I’d love to hear about it. I’m always open to learning and improving my knowledge.
Stay humble and keep learning!